

オープンソースソフトウェアを用いて Mixed-Solvent MDを実施し、タンパク質のホットスポットを可視化してみます。
実行環境
- OS: Ubuntu 22.04.3 LTS
- CPU: AMD Ryzen 7 5700X 8-Core Processor
- GPU: NVIDIA GeForce RTX 3060 Ti (8G)
- RAM: 32GB
CosolvKit について
CosolvKitは、OpenMMをベースとしたオープンソースのMixed-Solvent MD(混合溶媒分子動力学)解析ツールです。
創薬において、タンパク質上のホットスポット(リガンドの結合エネルギーに大きく寄与するタンパク質上の局所領域)を把握することは、Fragment-Based Drug Design(FBDD)や Structure-Based Drug Design(SBDD)の重要な出発点となります。
Cosolvkitでは、ベンゼンやアセトアミドなどの有機プローブを含む混合溶媒中でMDシミュレーションを実施し、プローブの分布からタンパク質上のホットスポットを可視化できます。
本記事では、Cosolvkitの環境構築から実際の実行方法、生成されるMapの見方までを確認していきます。
環境構築
※NVIDIAのGPU環境を想定しています。NVIDIAのGPUがない、あるいはGPUドライバーをインストールしていない環境では、適切な動作となりませんのでご注意ください。
Githubの内容を参考にconda環境の構築を行います。以下、私の環境で利用したコマンドです。
cd (任意のディレクトリ)
git clone https://github.com/forlilab/cosolvkit
cd cosolvkit
conda create -n cosolvkit -c conda-forge -f environment.yml -n cosolvkit
conda activate cosolvkit
pip install -e .Cosolvkit の操作
今回は、exampleの内容に沿って Mixed-Solvent MDを実施します。
リポジトリにアップロードされているタンパク質ファイルと、configファイルに設定されている5種のプローブ分子(ベンゼン、メタノール、プロパン、イミダゾール、アセトアミド)を利用し、100 nsのMDシミュレーションを実施した後、結果を可視化します。
Pythonコードの編集
2026年6月現在、コマンド実行時のエラー回避のために、クローンしたレポジトリ内のPythonコードを編集する必要があります。
cosolvkit/cosolvkit/cosolvent_system.py の479行目のインデントを編集(def前の半角スペースの削除)し、同じく479行目の「_setup_new_topology」関数に以下の通り引数を追加しましょう。
def _setup_new_topology(self, cosolvents_positions: dict, topology=None, positions=None) -> app.Modeller:また、解析時のエラー回避のために、cosolvkit/cosolvkit/analysis.pyの1013行目のリスト変数「colors」を以下のように編集しましょう。
colors = [
"marine", "orange", "magenta", "salmon", "purple",
"cyan", "yellow", "lime", "red", "blue",
"green", "pink", "violet", "teal", "white"
]Mixed-Solvent MD の実行
Cosolvkitのリポジトリに移動し、以下のコマンドを実行します。
create_cosolvent_system -c cosolvkit/data/config.json実行時間は私の環境で10時間弱でした。100 nsのMDシミュレーションを実行するため時間にはご注意ください。
試してはいませんが、シミュレーション時間を変更する場合は、cosolvkit/cosolvkit/simulation.pyの「run_simulation」関数の”simulation_steps”を直接いじる必要がありそうです。
また、Githubの説明では、defaultはMDシミュレーションを実行しないと書かれていますが、私がクローンした時点のリポジトリでは、実行する設定がdefaultとなっていましたのてご注意ください。
トラジェクトリの解析
Cosolvkitでは、MDシミュレーションの結果ファイル(トラジェクトリ)を解析するスクリプトも存在します。
今回は、試しにイミダゾールの挙動を解析してみます。結果が出力される”results”フォルダに移動し、以下のpythonファイル(report.py)を作成して実行しましょう。
from cosolvkit.analysis import Report
statistics_file = "statistics.csv"
traj_file_aligned = "trajectory_aligned.xtc"
top_file = "system.prmtop"
out_path = "report_IMI"
cosolvent_names = ["IMI"]
report = Report(statistics_file, traj_file_aligned, top_file,
cosolvent_names=cosolvent_names, out_path=out_path)
report.generate_report(
equilibration=True,
rdf=True,
rmsf=True,
avg_selection='protein',
align_selection='protein and name CA',
)
report.generate_density_maps(
cosolvent_names=cosolvent_names,
gridsize=0.375,
temperature=300,
use_atomtypes=True,
atomtypes_definitions='../cosolvkit/data/dacar_atomtypes.json',
)
report.generate_pymol_session(density_files=out_path)解析実行後、数分程度で”report_IMI”フォルダ内に解析結果が生成されます。
フォルダ内の.dxファイルには、プローブ分子の存在確率やエネルギーの安定を解析し、3次元のGridデータに落とし込んだ情報が含まれています。
また、.pseファイルはPyMOLのセッションファイルであり、これを開くことでPyMOL上でホットスポットを可視化することが可能です。
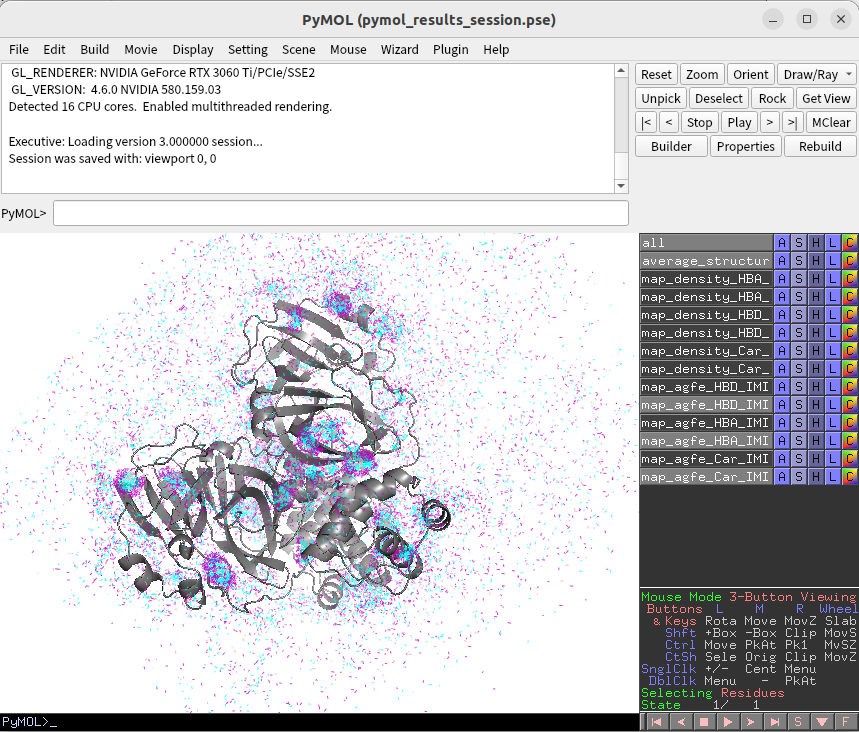
上記の画像は、イミダゾールの原子特性(Car: 芳香炭素、HBA: 水素結合受容体、HBD: 水素結合供与体)ごとに、Atomic Grid Free Energy(AGFE)が低い領域を可視化したものです。AGFEが低い領域ほど、その原子特性がエネルギー的に有利に存在しやすいホットスポットを示します。

拡大してタンパク質のSurfaceを可視化すると、プローブはポケットの領域に集中していることが確認できます。
Mixed-Solvent MDの解析からは、タンパク質上のホットスポットを特定できるだけでなく、「どのような官能基が好まれるか」という情報をもとにファーマコフォア仮説を立てることも可能です。
最後に
Cosolvkitを利用し、Mixed-Solvent MDとホットスポットの可視化までを実施しました。
同様の手法をオープンソースで実行する場合、GRROMACSやAmberToolsを利用する選択肢も考えられますが、環境構築の難易度が高く解析に至るまでに時間を要します。
Cosolvkitは改善の余地が残されている一方、環境構築が用意にできることため、取っ掛かりとしては非常に良いツールだと感じました。
プローブのクラスタリング機能が実装されれば、ファーマコフォアの抽出が容易になるため、より実務的なツールになるかもしれませんね。

コメント